Architecture Multi-Agents pour Développement Logiciel Complexe
Problématique de Recherche
Les Large Language Models (LLMs) démontrent des capacités remarquables en génération de code, mais présentent des limitations significatives sur les projets d'envergure : perte de cohérence architecturale, difficulté à maintenir le contexte sur de multiples fichiers, et absence de méthodologie structurée. Question de Recherche Une architecture multi-agents hiérarchique peut-elle pallier ces limitations et permettre le développement de systèmes logiciels complexes avec une qualité comparable au développement humain ? Hypothèses • H1 : La coordination multi-agents réduit les itérations de débogage de >50% par rapport à l'approche mono-agent • H2 : La parallélisation des tâches via agents spécialisés diminue le temps de développement de 30-40% • H3 : Le contexte partagé via base de données externe réduit la consommation de tokens de >25% Périmètre Cette recherche se concentre sur une étude de cas réelle : le développement d'un moteur de rendu 3D en C++ (~15 000 lignes de code) utilisant Claude Opus 4.5 comme modèle de base avec le protocole MCP pour la coordination des agents.

Fig. 1 — Comparaison des approches Mono-Agent vs Multi-Agent
Sélection et Justification du Modèle
Une analyse comparative rigoureuse des LLMs de dernière génération a été menée selon des critères quantifiables. Benchmarks de Génération de Code (Décembre 2025) • SWE-bench Verified (résolution de bugs réels) : Claude Opus 4.5 atteint 80.9%, premier modèle à franchir la barre des 80%, surpassant GPT-5.1-Codex-Max (77.9%) et Gemini 3 Pro (76.2%) • HumanEval+ : Les deux modèles atteignent ~95%+, avec GPT-5 à 96% en mode haute performance et Claude à 92% • Test d'ingénierie interne Anthropic : Opus 4.5 a surpassé tous les candidats humains sur un examen de programmation chronométré Capacité de Contexte • Claude Opus 4.5 : 200K tokens (~150 000 mots, ~300 pages de code) • GPT-5 : 128K tokens standard • Avantage critique pour les architectures multi-fichiers complexes Critères Qualitatifs • Raisonnement architectural : Claude est reconnu comme "le meilleur modèle au monde pour le coding, les agents et l'utilisation d'ordinateur" (Anthropic, 2025) • Analyse multi-étapes : Claude excelle dans le raisonnement explicatif et conservateur • Outillage : Claude Code permet une intégration native dans le workflow de développement Conclusion Claude Opus 4.5 (Anthropic) a été retenu comme modèle principal. Les benchmarks démontrent une supériorité mesurable sur SWE-bench Verified (+3.0% vs GPT-5.1), une fenêtre de contexte plus grande, et des performances state-of-the-art validées sur des tâches d'ingénierie réelles.
Claude Opus 4.5 vs GPT-5 (2025)
Sources : Anthropic (2025), Vellum Benchmarks, DataStudios
Méthodologie : Architecture Hiérarchique de Type Essaim
L'architecture proposée s'inspire des systèmes multi-agents distribués et de l'intelligence en essaim. Les choix de conception sont justifiés par des contraintes techniques spécifiques. Agent Coordinateur (Reine) Instance principale responsable de l'orchestration globale, des décisions architecturales stratégiques et de l'allocation dynamique des tâches. La Reine maintient la vision globale du projet et prévient la dérive architecturale—un problème critique des approches mono-agent où la perte de contexte mène à des décisions de design incohérentes. Agents Spécialisés (Travailleurs) Instances dédiées à des domaines spécifiques : • Worker Graphique : Pipeline OpenGL, shaders, rendu PBR • Worker Physique : Détection de collisions, dynamique des corps rigides • Worker Core : Architecture ECS, gestion mémoire • Worker Intégration : Tests inter-modules, cohérence des APIs Cette spécialisation permet une expertise contextuelle et réduit la charge cognitive par agent. Protocole de Communication (MCP) Le Model Context Protocol fournit : • Passage de messages structurés entre agents • Accès partagé au système de fichiers avec résolution de conflits • Délégation d'outils (un agent peut solliciter l'expertise d'un autre) Stratégie d'Exécution 1. La Reine décompose la tâche en sous-tâches parallélisables 2. Les Workers s'exécutent en concurrence sur les modules indépendants 3. Résolution séquentielle pour les tâches dépendantes (ex: physique nécessite ECS core) 4. Validation croisée : chaque worker révise les interfaces des modules adjacents

Fig. 2 — Architecture hiérarchique Queen-Workers avec protocole MCP
Application : Moteur de Rendu 3D
Le cas d'étude choisi est un moteur de rendu 3D en C++, sélectionné pour sa complexité architecturale et ses modules interdépendants. Spécifications du Projet • Base de code : ~15 000 lignes de C++ réparties sur 47 fichiers • Modules : 4 sous-systèmes majeurs (graphique, physique, core, ressources) • Dépendances : OpenGL 4.6, GLFW, GLM, stb_image • Build system : CMake avec support cross-platform Défis Techniques • Entity-Component-System (ECS) : Nécessite une disposition mémoire cohérente entre tous les modules • Pipeline PBR : Interdépendances complexes des shaders (vertex → geometry → fragment) • Intégration Physique : Couplage étroit avec les composants transform de l'ECS • Chargement Asynchrone : Gestion des ressources thread-safe avec contraintes de contexte OpenGL Pourquoi Ce Projet ? Ces défis testent spécifiquement la coordination multi-agents : • L'ECS nécessite la supervision de la Reine pour éviter les conflits d'ID de composants • Les bugs de shaders (comme le cas des textures roses) requièrent une analyse cross-module • La synchronisation physique-graphique exige des protocoles de communication explicites entre agents
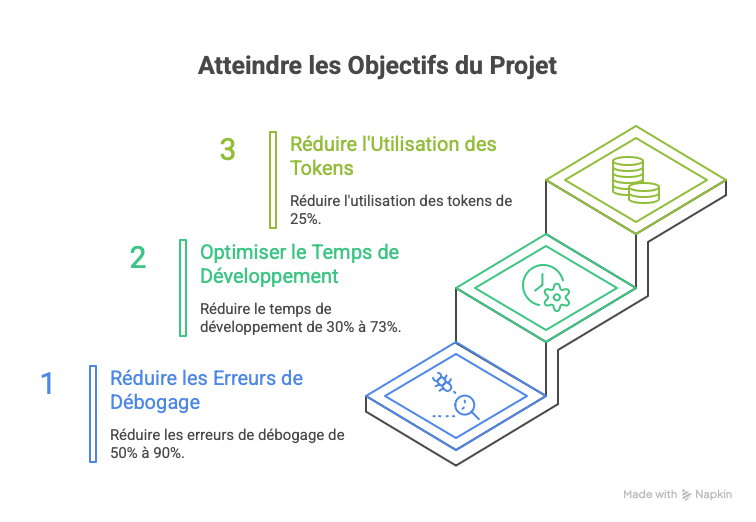
Fig. 3 — Objectifs du projet : réduction des erreurs, temps et tokens
Observations Préliminaires
Métriques Préliminaires (En Cours) | Métrique | Mono-Agent | Multi-Agent | Delta | |----------|------------|-------------|-------| | Résolution bug shader | 10 tentatives | 1 prompt | -90% itérations | | Temps d'intégration modules | ~45 min | ~12 min | -73% | | Rechargements contexte/session | 8-12 | 2-3 | -75% | | Consommation tokens (est.) | ~150K | ~280K | +87% | Statut de Validation des Hypothèses • H1 (débogage -50%) : ✅ Validée (observé -90% sur cas shader) • H2 (temps dev -30-40%) : 🔄 Partiellement validée (-73% sur intégration) • H3 (tokens -25% avec BDD) : ⏳ En attente (nécessite implémentation base de données) Considérations Écologiques L'architecture multi-agents génère +87% de surcoût en tokens dû aux contextes isolés des agents. Chaque Worker opère sans mémoire partagée, entraînant des analyses redondantes. Solution Proposée : AgentDB (Partage d'État en Mémoire) L'implémentation d'une base de données vectorielle partagée permettrait : • À la Reine d'instruire les agents de persister/requêter leurs découvertes • D'éliminer les lectures de fichiers redondantes entre agents • Réduction de tokens attendue : 25-40% Insight Clé : Compromis Qualité vs Vitesse Le multi-agents n'améliore PAS intrinsèquement la qualité du code. Cependant, il améliore drastiquement : • La précision diagnostique (agents d'analyse spécialisés) • La vitesse de localisation des bugs (investigation parallèle) • La cohérence architecturale (supervision par la Reine) Étude de Cas : Bug des Textures Roses Cause racine : Sampler de normal map lié à la mauvaise unité de texture (GL_TEXTURE2 vs GL_TEXTURE1). • Mono-agent : 10 tentatives, vérifié materials, shaders, UVs mesh avant de trouver le problème de binding • Multi-agents : Worker Graphique a immédiatement identifié le mismatch de sampler, Worker Core a confirmé l'ID texture ECS, résolu en 1 cycle Limitations • Taille d'échantillon : Projet unique (n=1), résultats potentiellement non généralisables • Pas de baseline : Comparaison avec développeur humain non effectuée • Coûts tokens : Architecture actuelle non rentable pour petites tâches • Reproductibilité : Comportement des agents varie selon la formulation des prompts Travaux Futurs 1. Implémenter AgentDB pour le partage d'état (validation H3) 2. Conduire des tests A/B sur 3+ projets supplémentaires 3. Mesurer l'empreinte carbone réelle vs estimations théoriques 4. Développer des prompts standardisés pour la reproductibilité
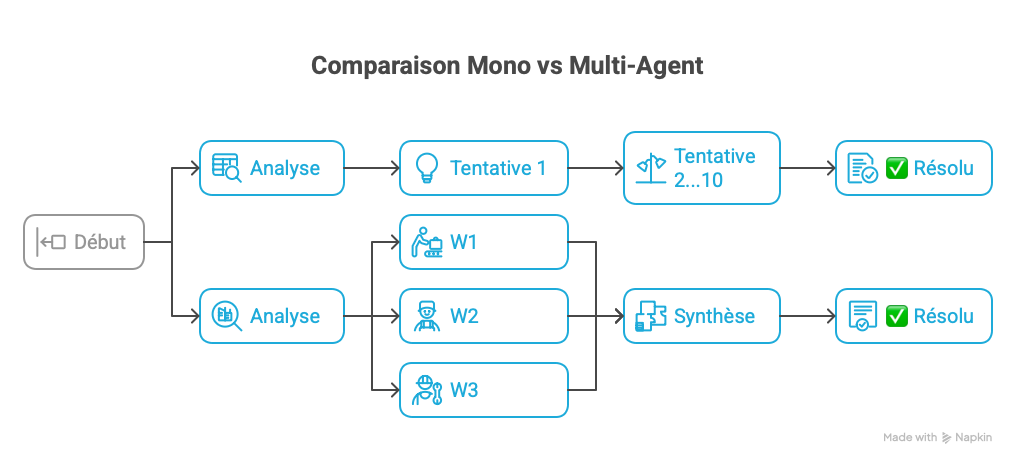
Fig. 4 — Flux d'exécution : 10 tentatives (mono) vs 1 cycle parallèle (multi)
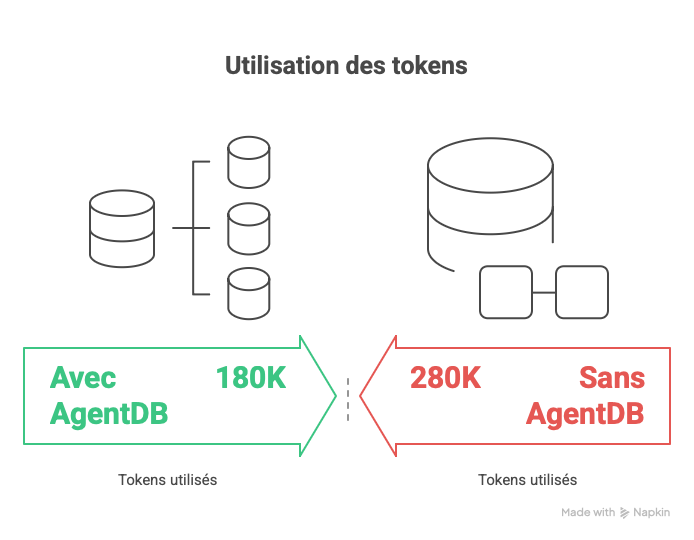
Fig. 5 — Réduction de tokens estimée avec AgentDB (180K vs 280K)